
Friday, November 3, 2017
Wednesday, October 25, 2017

Relativity Fest 2017 Review – Part I
The Popsicle Moment
This is the first in a two-part review of Relativity Fest 2017. Part two is titled – Relativity Fest 2017 Review – Part II – The Rise of The Machine. Subscribe to ESI Gladiator to receive notification when it's published tomorrow.
Introduction
The verdict - TWO
THUMBS UP!
This was my very first Relativity Fest! That’s right, I went kicking and screaming
into the den of the dragon I have somehow avoided all these years. Avoidance of Relativity has not been by accident. Like other old industry war horses, I’ve used
virtually every “eDiscovery” application that’s hit the market over the past 25
years, but not Relativity. Not until past few years. I am no
different than the average consumer – I have my favorites. My favorite historically has not been
Relativity, for reasons that are unimportant here.
Like many service providers in the industry these days, the company
I work for offers clients options. A few
years back, a client pulled us into both Eclipse AND Relativity. That law firm client has an even mix of Relativity
and Eclipse cases. Even though we have
our own review software, Recenseo, and highly
advanced “predictive analytics” application, Envize, we had to bring in the
technology the customer wants. Of
course, we believe our technology is just as good as those other guys. Yet, we now support substantial matters in
all three review tools. Clients have
choices. We are not alone; many
providers now offer multiple options.
FTI, one of the largest companies in our space, recently announced that
it has rolled out Relativity and spoke about why during the keynote speech at R
Fest 2017. Yes, that’s the same FTI that
bought both Attenex and Ringtail. More
on that in Part II.
We are rapidly reaching the point where you can get a wide
variety of technology on any street corner.
So how does a consumer differentiate between “providers”? Service – create those Popsicle Moments. What the heck is a Popsicle Moment? Read on.
Wednesday, August 30, 2017

Do You Agree to Untested Search Terms?
Introduction
Unless you are using a proven key term validation methodology
that utilizes sampling, you are almost certain to agree to terms that are likely
overly broad. Obviously, agreeing to
terms that are overly broad is costly, but common. The greater risk - what are you missing?
Too many declare that search terms "look good" without the appropriate testing.
Monday, August 14, 2017

ePizza as a Service – Cloud Explained (OP, IaaS, PaaS and SaaS)
By Mark G. Walker, VP Advisory Services and Susan Kavanagh, Senior Advisor -iControl ESI
Introduction
We recently came across again this LinkedIn post from 2014 by Albert Barron, a software architect at IBM. His analogy does a great job of explaining the various “… as a service” models using everyone’s food favorite – PIZZA!!!. We are taking a few liberties with Albert’s original version and hope he doesn’t mind.
Tuesday, July 25, 2017

Top Adviser warns of out-of-control autonomous robot lawyers
Mark Walker, an eDiscovery adviser, author and frequent commentator, advocated Wednesday for "creating rules that govern how we use Artificial Intelligence (AI) with legal technology lest we unleash on humanity a set of autonomous robot lawyers that we don't know how to control.”
“I’ve spent my entire adult life serving lawyers. Non-lawyers like myself have a hard-enough time now getting the human kind to listen", Walker stated.
Thursday, July 6, 2017

Is AI Replacing Lawyers and their Staff?
By Mark G. Walker, VP Advisory Services and Susan Kavanagh, Senior Advisor -iControl ESIIntroduction
Don’t shoot the messenger! You can’t make this stuff up. Or can you? There have been several articles recently suggesting that Artificial Intelligence (AI) is creeping into the legal arena and that “Lawyers could be the next profession to be replaced by computers”. That’s literally the title of a recent CNBC “Future of Work” article.
“The legal profession — tradition-bound and labor-heavy — is on the cusp of a transformation in which artificial-intelligence platforms dramatically affect how legal work gets done.”
Monday, June 12, 2017

How do I prove that TAR makes sense?
By Mark Walker, VP Advisory
Services at iControl ESI
Please post a response with your thoughts, especially if you
disagree with any of this, or I get anything wrong. This post is intended to
prompt discussion on this topic.
Introduction
When does it make sense to use a
TAR workflow? Those of us that work with predictive analytics (a/k/a predictive
coding) and TAR workflows have been asked this question more times than we can
count. The answer is usually the unpopular “it depends” response. At the end of
the day, there should be a cost vs. benefit math exercise. However,
non-monetary factors can also impact the decision. The time allotted to get the
production out the door, resources available, and the budget are also factors.
Even case strategy can factor into the equation. There are a lot of variables.
Virtually everyone agrees that in most cases we simply cannot review everything.
Most just resort to using date, file type and search term filters. We can do
better.
Those
of us that have been using TAR workflows for years know that a well-planned TAR
workflow using machine learning (preferably active learning) will save both
time and money. We know that using the right technology is highly accurate when
based upon sound sampling methods where humans teach the technology to find
what they seek. But how do we prove it to someone who has never traveled that
road? Lawyers are all about proof. That’s what they do. We have a tough
audience..

Defining the Problem
A few weeks ago, I reconnected with
a LitSupport manager at a major law firm. He has been in the industry a very
long time and closely follows the most cutting-edge technology. As a LitSup
manager, he has had success convincing lawyers within his firm to use TAR
workflows. Well, some of them. This time, I asked him the dreaded question, but
in a slightly difference way – “What kind of cases should your lawyers consider
using predictive analytics.” His answer, tongue in cheek: “Every Case!” We both
got a good chuckle out of that answer. While we chuckled, he is exactly right.
But, like everyone else in the industry, he is also frustrated with the
industry as a whole’s inability to make the argument in a way that resonates
with lawyers. Some use fear to convince – if you don’t do it, others will.
Lawyers like litmus tests. Bright lines. They don’t like grey. Lawyers don’t
react well to threats and attempts to invoke fear.
When reviewing documents, lawyers
want documents that are relevant. Sure, good lawyers are concerned about cost
and one would think would be interested in anything that will make them more
efficient. But, they are also concerned about risk and trust.
Here’s the root of the problem:
Relevancy rates in collected documents are often as low as 1% in most cases.
That means 99 out of every 100 documents collected have no value. Sure, there
are exceptions, but it is rare that a document review relevancy rate is above
50% using traditional search and review work flows. No matter how you cut it,
when 50% of what you review (best case) is wasted effort, there is an expensive
problem that needs to be solved. By the way, a search and review workflow that
achieves a 50% reduction and relevancy rate is a phenomenal achievement. We
traditionally see closer to 30% without leveraging a TAR workflow. We can do
better! We must get as close to the 1% we seek as possible.
Using a document count litmus test
to determine whether to use predictive analytics doesn’t work. For example,
“use predictive analytics when you have 10,000 documents to review”. The
average single custodian (witness) has on average 10,000 documents collected.
If 1% of that is what we expect to be relevant, then out of 10,000 documents
your seeking 100 that are relevant. There are too many other factors that might
make it more cost effective to just review the 10,000 documents. Document count
is not the right litmus test.

Solving the Problem - Do the math
Using our 10,000 document, single
custodian example, we arrive at a conservative 50% relevancy rate litmus test.
That is, if you expect that whatever method you use to filter down before
review will yield less than a 50% relevancy rate during review, then it makes
sense for you to deploy TRUSTED predictive analytics technology to your review,
often in conjunction with validating search terms to exchange with the
opposition. See
Combining Search and Predictive Coding in 5 Easy Steps. While you can’t
really know for certain what the actual relevancy rate will be up front,
obviously, we can usually have a pretty good idea if it’s going to be above
50%.

In our 10,000-document example
using a traditional filter, search and review methods, one might cut the review
in half and only review 5,000 documents. At a billing rate of $250 per hour,
and a typical review rate of 55 docs per hour, the cost to review 5,000
documents is $22,727.27. $250 an hour is low compared to the market rate for
associates. Make your estimates conservative.
If predictive analytics rate is
$0.06 per document, the cost to classify with predictive analytics the 10,000
documents available for review is $600. All other technology costs such as
processing and hosting will be incurred no matter what review method you chose.
Leveraging predictive analytics,
you should typically see an 80% or above relevancy rate during review. If you
only achieve 50% using traditional search and review, then spending $600 on
analytics achieves at least 30% improvement, which is very conservative.
Therefore, in this very conservative example you reduce the review by 1,500
documents and avoid 27.7 hours of review time. At $250 per hour, that’s
$6,818.18 of review cost avoided. Since the analytics cost just $600, the net
savings is $6,218.18. How can anyone ignore that advantage?
Ah, naysayers might say, we are
going to use contract reviewers at $55 per hour! Even with the dramatically reduced billing rate, there is still a net savings
of $900, and don’t discount speed either.


Predictive Analytics is not just for Big cases anymore.
In the example above, we’ve used a
very small case - a 10,000 document case hosted in a review platform is, well,
rare these days. Many of the cases we deal with are multi-million document
cases. 100,000 hosted is common. Using the same modeling as outlined above, the
savings achieved on a 100,000-document population is persuasive and undeniable.

At a $250 per hour review rate

At a $55 per hour review rate
Conclusion
With very few exceptions,
leveraging a TAR workflow that includes predictive analytics (a/k/a predictive
coding) will save considerable time and money. The courts have been encouraging
lawyers to leverage technology. Clients are demanding their outside counsel
reduce costs. Fixed fee arrangements are
becoming common place where lawyers have skin in the game to keep the time they
spend on matters low. For contingent fee lawyers, time really is money.
Do the math yourself. Apply
whatever assumptions you feel appropriate. Increase document decisions per
hour, lower hourly rates, increase the per doc cost of analytics. What you will
find is that using even the most extreme and efficient methodology, leveraging
predictive analytics simply makes financial sense for everyone involved. Reach
out to me and I’ll provide you with a calculator so you can input your own
assumptions.
So, what’s keeping you from
leveraging predictive analytics? Inquiring minds want to know.
Monday, March 6, 2017

Parts 4 & 5: Combining Predictive Coding and Search Term Classification in 5 Easy Steps
By Mark G. Walker, VP Advisory Services and
Robin Athlyn Thompson, VP Marketing | Business Development
By popular demand, we are releasing Steps 4 & 5 together. In case you missed Part 1, you can find it here. You can find part 2 here, and part 3 here.
Introduction to Steps 4 & 5.
Steps 4 & 5 are frequently performed in parallel. When available, predictive coding is beneficial in validating key terms.
Step 4: Validate Key Terms Before You Agree to Them
There
are those of us who have spent decades developing key term validation
protocols, keeping the attorneys involved on task, and hopefully convincing
them not to agree to poor key terms.
Poor key terms can, and frequently do, return 70%, 80%, even more than
90% documents that have little or no value to the case. Key terms are usually overly broad. In the search-world we call this “over-fitting,”
A certain amount of over-fitting is desirable, as you don’t want to be too
narrow with key terms as something can be missed. On the other hand, you don’t want to be too
broad, because the more you must review, the greater the cost and the more
likely it will be that the opposition will fuss about dumping. Not that dumping ever happens in this
business! Just like Goldilocks and the
three bears, we’re aiming for key terms that are just right.
There are entire protocols and technology features dedicated
to validating search terms.
Oversimplified, a search term validation process is one that is
repeatable and contains quality control measures. Documents hitting a proposed set of search
terms are “sampled” and those samples are reviewed and scored.
Key Term
|
Hits Sampled
|
Tagged Relevant
|
% Relevant
|
Diamond
|
100
|
20
|
20%
|
Joe
|
100
|
10
|
10%
|
Imagine a case about a fictional restaurant called Diamond
Joe’s. The restaurant chain is owned by
the fictional company Diamond Joe Holding.
The majority shareholder is the fictional Joe Diamond. Joe owns an interest in many companies, some
completely unrelated to the subject of the litigation, the restaurant
chain. Joe owns a diamond mine in South
Africa – Joe’s Diamond Mines. Joe also
owns a chain of jewelry stores in South Texas and Mexico. Finally, Joe owns a
minor-league baseball team named, you got it – The Diamondbacks. As you might imagine, searching Joe Diamond’s
email collection along with 50 of his employees will yield a great number of
“false positives” using the terms diamond and Joe. Of course, that seems obvious in this
example, but there are many terms that have multiple meanings and depend on
context. Sampling hits of those terms,
along with any others you have, will eventually ferret out which terms can be
changed by, dropping some terms like Joe and diamond, and/or adding other
terms, proximity connectors and other tweaks to existing and new terms. Search term validation protocols are very
effective in doubling and even tripling the relevancy rate of documents that
you ultimately must review. The cost
savings is dramatic because even without leveraging advanced technology
outlined in Step 5, far fewer documents are reviewed and of those reviewed; far
fewer are of no value.
On large projects, search term validation protocols can be
tedious, but are necessary. Your
protocol must be repeatable, reportable, and iterative with validation and
verification. While sound key term
validation protocols get you to the same place, the road is much shorter when
you measure key term effectiveness as you conduct your sampling using the
advanced analytics and strong key term reporting as outlined in Step 5.
Step 5: Leverage Smart Technology

Before classifying ESI in an
analytics engine, perform any additional objective filtering that you can to
eliminate ESI that has no value in a text classification engine, or is known to
be irrelevant. As previously discussed,
audio and video files, image only file formats can often be eliminated from
classification. Eliminate ESI that may
have survived prior filters, and sometimes can more easily be identified once
in the review platform where predictive coding is delivered and available. Establish a separate work flow for files that
can’t be classified. If your using the right technology and provider, this will
be part of their standard process, but be certain.
Advanced analytics, such as predictive coding or machine
learning, is not new. The technology and
methods that underlay analytical engines has been in use, well, since computers
to run them have existed. In eDiscovery
and Information Governance software platforms, predictive coding technology has
been available for well over a decade.
However, it is only recently that lawyers and judges have truly begun to
become comfortable with Predictive Coding technology and associated
workflows. Predictive Coding is a large
bucket of all types of analytics tools, all of which are useful for different
reasons. Here, however, we are focused
solely on machine learning. Machine
learning (ML) is the sub-field of computer science that gives computers the
ability to learn, without being explicitly programmed (Arthur Samuel, 1959). (Samuel, 2000) ML evolved from the study of pattern recognition
and the computational learning theory in artificial intelligence. (Encyclopedia
Britannica, n.d.) Sounds a bit like rocket science? Well, at its core, technology built on
machine learning is full of complex algorithms, equations, hyper-planes and all
kinds of complex things that frankly none of us really need to understand. To someone like me, it is rocket
science. What we do need to understand
is this: ML allows you to review samples of documents, mark them relevant or not
relevant, and the technology will classify everything based upon human review
of those exemplars. The technology finds
everything that is like those documents that are marked as relevant or not
relevant. Like any evolving technology,
however, you must make sure you have a basic understanding of the technology
you intended to use.
Many of the ML
engines used for predictive coding today were not originally built for
predictive coding. They were in fact
built on methodologies and algorithms intended for concept classification
analytics and visualization (reporting) of concepts. The clear majority of the predictive coding
engines on the market today, are passive learning applications. Passive learning applications classify ESI as
a snapshot in time. You then review
representative conceptual samples from the target population that are randomly
selected by the application you are using.
Once the sample is reviewed, the ML engine determines what it thinks is
relevant or not relevant based on that snapshot. Many samples are reviewed in this process,
and sometimes many re-classifications must occur. Because a passive engine is a static snapshot
of the data, samples must be larger in number, and there are many starts and
stops as you train the machine to determine what is relevant as opposed to what
is not relevant. Like search term
validation protocols without ML, with passive ML you get to the same spot down
the road as an active learning ML, it just takes you longer to get there. One has to review dramatically more samples
and you must have substantial assistance to conduct reclassification and to
measure stability.” Stability is that
point where you know that the machine has learned all it is going to learn from
samples, and it is time to stop training and conduct quality control
audits. Determining stabilization in a
passive learning based tool can be challenging.

Active learning ML-based technology is different. Active learning engines are usually based
upon binary methods and algorithms such as Support Vector Machine (SVM), for
example (Saha, Hasan, Burgess, Habib,
& Johnson, 2015) .
Active learning changed the game with respect to speed and
efficiency. The biggest advantage to the
consumer, is that the engine continually and “actively” reclassifies what is
relevant as the sample review is being conducted. With the right active learning engine, this
reclassification happens virtually in real time no matter the number of
reviewers. Feedback on how you are doing
is also immediate and continuous.
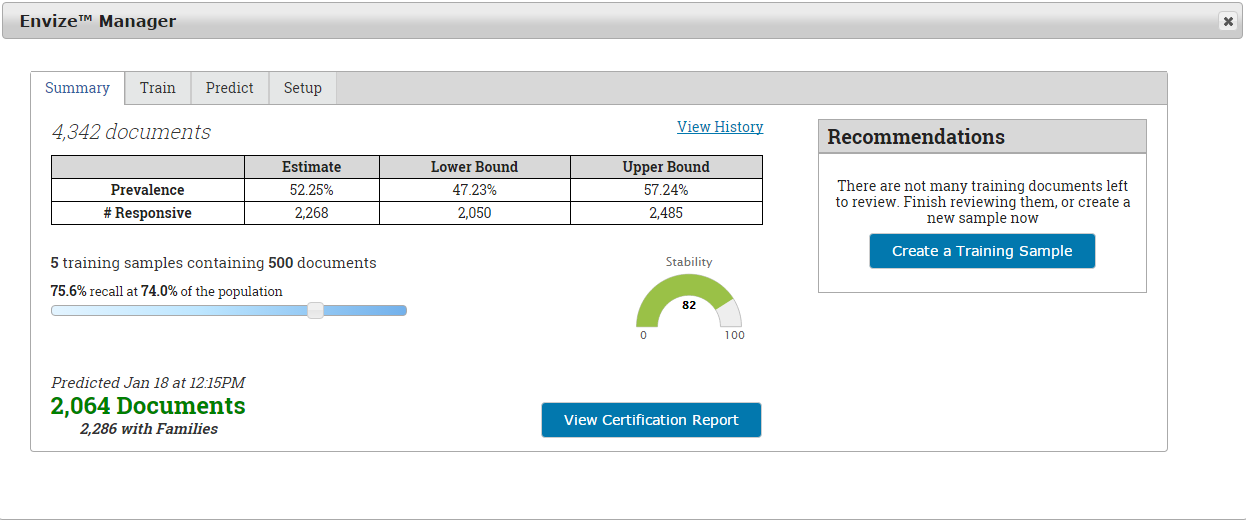
So how does ML help with the all-important key term
validation? Simple: because the
classification engine is classifying all documents in a targeted ESI
population, allowing you to grade the effectiveness as you go, you have
real-time feedback on search term effectiveness - assuming, of course, that the
technology you are using has strong key term hit reporting. With ML you are not limited to just the
sample documents that you review. The
machine takes what has been reviewed, and then extrapolates that to the entire
population of data. Your search term hit
report can then provide a relevancy hit rate across all data, not just what has
been reviewed. As learning stabilizes,
so too do the key terms, allowing you to quickly determine which terms need
work. The technology will often suggest
terms by showing you those terms that are most common in relevant documents.
Once learning has stabilized, follow a well-established audit
sample review to make sure that you agree that the learning has
stabilized. It is then time to move on
to privilege review and production.
Conclusion
Well-established filtering, key term validation and machine
learning workflows are becoming common place and for very good reason – combining
the two has proven over and over to save considerable time and money by
eliminating ESI that has no value. In
our world, time is indeed money.
References
Enclycopedia Britannica. (n.d.). Machine Learning.
Retrieved from Britannica:
http://www.britannica.com/EBchecked/topic/1116194/machine-learning
National Institutes of Standards and Technoloy.
(n.d.). National Software Reference Library. Retrieved from National
Software Reference Library: https://www.nist.gov/programs-projects/national-software-reference-library
Saha, T., Hasan, M., Burgess, C., Habib, M., &
Johnson, J. (2015). Batch-mode active learning for technology-assisted review. Big
Data (Big Data), 2015 IEEE International Conference on (pp. 1134-1143).
Santa Clara, California: IEEE.
Samuel, A. (2000). Some Studies in Machine Learning
Using the Game of Checkers. IBM Journal of Research & Development,
44(1/2), 207.
Wednesday, March 1, 2017

Part 3: Combining Predictive Coding and Search Term Classification in 5 Easy Steps
By Mark G. Walker, VP Advisory Services and
Robin Athlyn Thompson, VP Marketing | Business Development
Step 3: Process the Good Stuff

Once processing is complete, apply your “objective” filters
identified in Step 2 again so that you can identify files coming from
containers that can be suppressed from downstream processes.
Unlike prior workflows centered on applying search term
filters at this stage, you SHOULD NOT filter by search terms during processing,
unless you’re using terms that are validated using a process outlined in Step 4
and will not change going forward. Even
those of us expert at developing search terms should remember that using those
search terms during processing may result in pulling a large percentage of
irrelevant documents. The fact is we
can’t be certain how well search terms perform until we perform sample review
and testing. At minimum, we encourage
you to perform these minimum tasks discussed here.
Finally, as processing extracts domains, we recommend you seek a report of domains present in the ESI and filter-out emails from domains that are clearly junk. Emails from cnn.com, for example, may be clear spam emails. Some processing applications have rudimentary review and tag functions designed precisely for this purpose. Be careful, however, as anything you do in terms of filtering during processing can have a negative impact downstream. Regardless of whether you filter out junk domains during processing, you will want to do that step (again if you did so during processing) once the ESI resides in the review/analysis platform. Here are a few things to consider during processing. This is not intended to be an exhaustive list.
- Apply Objective Filters – Apply again any objective filters that where applied during Step 2.
- Consider “Pre-Processing” steps – It may dramatically speed up processing to utilize a multi-stage processing work flow. For example, you may not want to extract text and conduct indexing on files that may be filtered out.
- Be Careful with Search Terms - Before applying search term filters during processing, consider very carefully the consequences. There are serious ramifications to deduplication, for example, if your search terms change and you receive new data that may apply a different set of terms.
- Domain Filters – identify junk domains and eliminate files associated with clearly junk emails.
Stay tuned next week for Part 4: Validate Key Terms Before You Agree to Them
Subscribe to:
Posts (Atom)