
Parts 4 & 5: Combining Predictive Coding and Search Term Classification in 5 Easy Steps
By Mark G. Walker, VP Advisory Services and
Robin Athlyn Thompson, VP Marketing | Business Development
By popular demand, we are releasing Steps 4 & 5 together. In case you missed Part 1, you can find it here. You can find part 2 here, and part 3 here.
Introduction to Steps 4 & 5.
Steps 4 & 5 are frequently performed in parallel. When available, predictive coding is beneficial in validating key terms.
Step 4: Validate Key Terms Before You Agree to Them
There
are those of us who have spent decades developing key term validation
protocols, keeping the attorneys involved on task, and hopefully convincing
them not to agree to poor key terms.
Poor key terms can, and frequently do, return 70%, 80%, even more than
90% documents that have little or no value to the case. Key terms are usually overly broad. In the search-world we call this “over-fitting,”
A certain amount of over-fitting is desirable, as you don’t want to be too
narrow with key terms as something can be missed. On the other hand, you don’t want to be too
broad, because the more you must review, the greater the cost and the more
likely it will be that the opposition will fuss about dumping. Not that dumping ever happens in this
business! Just like Goldilocks and the
three bears, we’re aiming for key terms that are just right.
There are entire protocols and technology features dedicated
to validating search terms.
Oversimplified, a search term validation process is one that is
repeatable and contains quality control measures. Documents hitting a proposed set of search
terms are “sampled” and those samples are reviewed and scored.
Key Term
|
Hits Sampled
|
Tagged Relevant
|
% Relevant
|
Diamond
|
100
|
20
|
20%
|
Joe
|
100
|
10
|
10%
|
Imagine a case about a fictional restaurant called Diamond
Joe’s. The restaurant chain is owned by
the fictional company Diamond Joe Holding.
The majority shareholder is the fictional Joe Diamond. Joe owns an interest in many companies, some
completely unrelated to the subject of the litigation, the restaurant
chain. Joe owns a diamond mine in South
Africa – Joe’s Diamond Mines. Joe also
owns a chain of jewelry stores in South Texas and Mexico. Finally, Joe owns a
minor-league baseball team named, you got it – The Diamondbacks. As you might imagine, searching Joe Diamond’s
email collection along with 50 of his employees will yield a great number of
“false positives” using the terms diamond and Joe. Of course, that seems obvious in this
example, but there are many terms that have multiple meanings and depend on
context. Sampling hits of those terms,
along with any others you have, will eventually ferret out which terms can be
changed by, dropping some terms like Joe and diamond, and/or adding other
terms, proximity connectors and other tweaks to existing and new terms. Search term validation protocols are very
effective in doubling and even tripling the relevancy rate of documents that
you ultimately must review. The cost
savings is dramatic because even without leveraging advanced technology
outlined in Step 5, far fewer documents are reviewed and of those reviewed; far
fewer are of no value.
On large projects, search term validation protocols can be
tedious, but are necessary. Your
protocol must be repeatable, reportable, and iterative with validation and
verification. While sound key term
validation protocols get you to the same place, the road is much shorter when
you measure key term effectiveness as you conduct your sampling using the
advanced analytics and strong key term reporting as outlined in Step 5.
Step 5: Leverage Smart Technology

Before classifying ESI in an
analytics engine, perform any additional objective filtering that you can to
eliminate ESI that has no value in a text classification engine, or is known to
be irrelevant. As previously discussed,
audio and video files, image only file formats can often be eliminated from
classification. Eliminate ESI that may
have survived prior filters, and sometimes can more easily be identified once
in the review platform where predictive coding is delivered and available. Establish a separate work flow for files that
can’t be classified. If your using the right technology and provider, this will
be part of their standard process, but be certain.
Advanced analytics, such as predictive coding or machine
learning, is not new. The technology and
methods that underlay analytical engines has been in use, well, since computers
to run them have existed. In eDiscovery
and Information Governance software platforms, predictive coding technology has
been available for well over a decade.
However, it is only recently that lawyers and judges have truly begun to
become comfortable with Predictive Coding technology and associated
workflows. Predictive Coding is a large
bucket of all types of analytics tools, all of which are useful for different
reasons. Here, however, we are focused
solely on machine learning. Machine
learning (ML) is the sub-field of computer science that gives computers the
ability to learn, without being explicitly programmed (Arthur Samuel, 1959). (Samuel, 2000) ML evolved from the study of pattern recognition
and the computational learning theory in artificial intelligence. (Encyclopedia
Britannica, n.d.) Sounds a bit like rocket science? Well, at its core, technology built on
machine learning is full of complex algorithms, equations, hyper-planes and all
kinds of complex things that frankly none of us really need to understand. To someone like me, it is rocket
science. What we do need to understand
is this: ML allows you to review samples of documents, mark them relevant or not
relevant, and the technology will classify everything based upon human review
of those exemplars. The technology finds
everything that is like those documents that are marked as relevant or not
relevant. Like any evolving technology,
however, you must make sure you have a basic understanding of the technology
you intended to use.
Many of the ML
engines used for predictive coding today were not originally built for
predictive coding. They were in fact
built on methodologies and algorithms intended for concept classification
analytics and visualization (reporting) of concepts. The clear majority of the predictive coding
engines on the market today, are passive learning applications. Passive learning applications classify ESI as
a snapshot in time. You then review
representative conceptual samples from the target population that are randomly
selected by the application you are using.
Once the sample is reviewed, the ML engine determines what it thinks is
relevant or not relevant based on that snapshot. Many samples are reviewed in this process,
and sometimes many re-classifications must occur. Because a passive engine is a static snapshot
of the data, samples must be larger in number, and there are many starts and
stops as you train the machine to determine what is relevant as opposed to what
is not relevant. Like search term
validation protocols without ML, with passive ML you get to the same spot down
the road as an active learning ML, it just takes you longer to get there. One has to review dramatically more samples
and you must have substantial assistance to conduct reclassification and to
measure stability.” Stability is that
point where you know that the machine has learned all it is going to learn from
samples, and it is time to stop training and conduct quality control
audits. Determining stabilization in a
passive learning based tool can be challenging.

Active learning ML-based technology is different. Active learning engines are usually based
upon binary methods and algorithms such as Support Vector Machine (SVM), for
example (Saha, Hasan, Burgess, Habib,
& Johnson, 2015) .
Active learning changed the game with respect to speed and
efficiency. The biggest advantage to the
consumer, is that the engine continually and “actively” reclassifies what is
relevant as the sample review is being conducted. With the right active learning engine, this
reclassification happens virtually in real time no matter the number of
reviewers. Feedback on how you are doing
is also immediate and continuous.
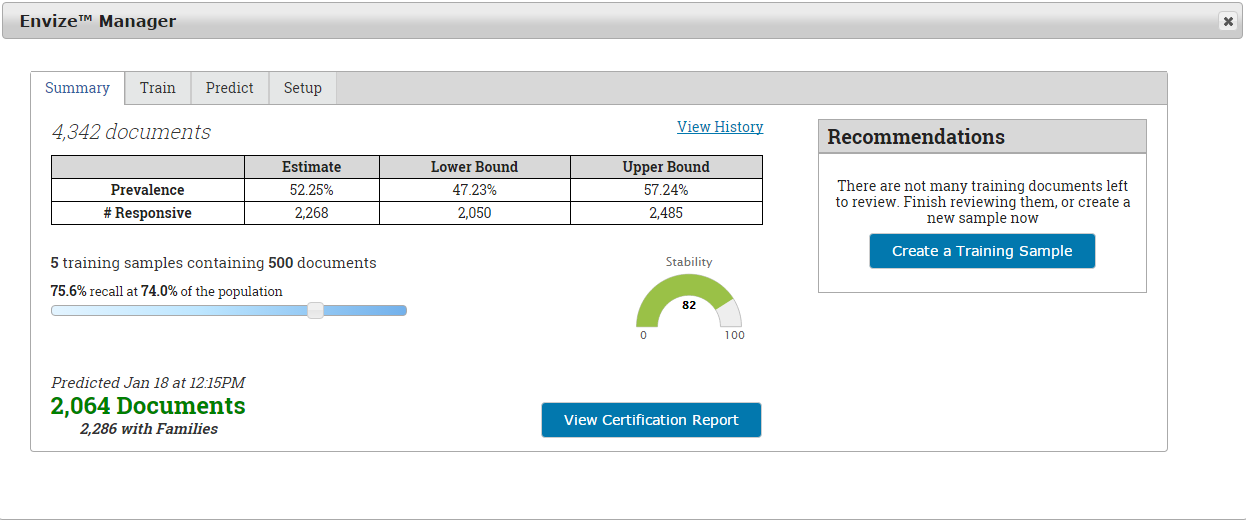
So how does ML help with the all-important key term
validation? Simple: because the
classification engine is classifying all documents in a targeted ESI
population, allowing you to grade the effectiveness as you go, you have
real-time feedback on search term effectiveness - assuming, of course, that the
technology you are using has strong key term hit reporting. With ML you are not limited to just the
sample documents that you review. The
machine takes what has been reviewed, and then extrapolates that to the entire
population of data. Your search term hit
report can then provide a relevancy hit rate across all data, not just what has
been reviewed. As learning stabilizes,
so too do the key terms, allowing you to quickly determine which terms need
work. The technology will often suggest
terms by showing you those terms that are most common in relevant documents.
Once learning has stabilized, follow a well-established audit
sample review to make sure that you agree that the learning has
stabilized. It is then time to move on
to privilege review and production.
Conclusion
Well-established filtering, key term validation and machine
learning workflows are becoming common place and for very good reason – combining
the two has proven over and over to save considerable time and money by
eliminating ESI that has no value. In
our world, time is indeed money.
References
Enclycopedia Britannica. (n.d.). Machine Learning.
Retrieved from Britannica:
http://www.britannica.com/EBchecked/topic/1116194/machine-learning
National Institutes of Standards and Technoloy.
(n.d.). National Software Reference Library. Retrieved from National
Software Reference Library: https://www.nist.gov/programs-projects/national-software-reference-library
Saha, T., Hasan, M., Burgess, C., Habib, M., &
Johnson, J. (2015). Batch-mode active learning for technology-assisted review. Big
Data (Big Data), 2015 IEEE International Conference on (pp. 1134-1143).
Santa Clara, California: IEEE.
Samuel, A. (2000). Some Studies in Machine Learning
Using the Game of Checkers. IBM Journal of Research & Development,
44(1/2), 207.

